Panoramica completa sull’Intelligenza Artificiale (IA), partendo dai suoi fondamenti storici e tecnologici fino ad arrivare alle applicazioni contemporanee e alle sfide future.
1. Fondamenti e Contesto Storico dell’Intelligenza Artificiale
Le sue origini concettuali risalgono alla Seconda Guerra Mondiale e alle esigenze della cyber war, ma lo sviluppo concreto ha subito una battuta d’arresto tra gli anni ’60 e ’70. Questo “periodo di stasi” fu causato principalmente dalla scarsità di dati digitali e da una capacità di calcolo insufficiente per addestrare modelli complessi.
La rinascita dell’IA è avvenuta a partire dal 2010, spinta da tre fattori principali:
- l’esplosione dei dati: la diffusione di smartphone e social media ha reso disponibile una quantità senza precedenti di dati.
- L’aumento della potenza di calcolo: l’adozione delle GPU (Graphics Processing Unit), sebbene meno potenti delle CPU in compiti sequenziali, si è rivelata ideale per l’IA grazie alla loro capacità di eseguire calcoli massivamente paralleli, riducendo drasticamente i tempi di latenza nell’addestramento dei modelli.
- L’ottimizzazione degli algoritmi: tecniche come la “distillazione”, che permette di trasferire la conoscenza da modelli grandi a versioni più piccole e agili, hanno reso l’apprendimento più efficiente anche con set di dati ridotti.

2. I Pilastri dell’IA Moderna: Machine Learning e Deep Learning
Il cuore dell’IA moderna si basa su due concetti interconnessi:
- Machine Learning (Apprendimento Automatico): algoritmi progettati per apprendere pattern e prendere decisioni dai dati, senza essere stati programmati esplicitamente per ogni singolo scenario.
- Deep Learning (Apprendimento Profondo): una branca del Machine Learning che utilizza reti neurali artificiali con molteplici strati (“deep”). Questo approccio stratificato permette al modello di apprendere caratteristiche sempre più complesse e astratte in modo incrementale, scomponendo un problema complesso in passaggi più semplici.
Quando un utente interagisce con un LLM, l’input viene scomposto in “token” (unità di significato) e analizzato attraverso database vettoriali per identificare i concetti più vicini e coerenti, generando così una risposta pertinente.

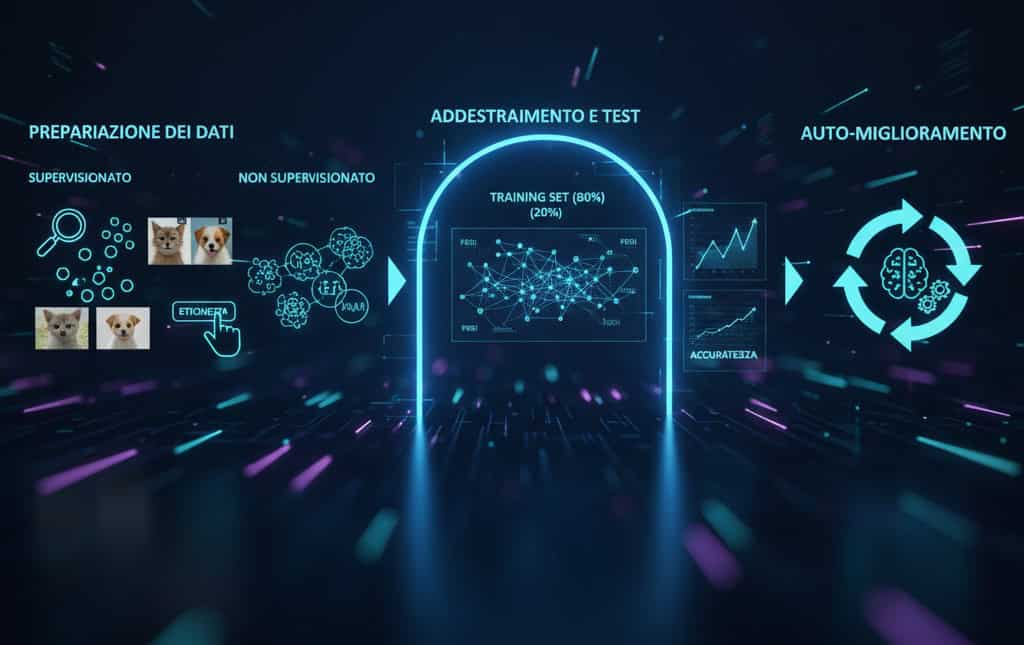
3. Il Funzionamento di un Modello IA: Dal Dato all’Output
Il ciclo di vita di un sistema IA è stato descritto in tre fasi fondamentali:
- Preparazione dei Dati: raccolta, pulizia ed etichettatura dei dati. L’addestramento può essere supervisionato, se i dati sono etichettati esplicitamente, o non supervisionato, se il sistema deve identificare autonomamente le strutture latenti nei dati.
- Addestramento (Training) e Test: una parte del dataset viene usata per addestrare il modello, mentre una parte separata (il test set) serve a valutarne le performance e l’accuratezza. Durante l’addestramento, il modello regola i “pesi” delle connessioni nella sua rete neurale, che sono i parametri numerici che determinano l’importanza di ciascun input nel calcolo del risultato finale.
- Auto-miglioramento: i modelli più avanzati sono in grado di auto-ottimizzare i propri parametri, avviando un percorso di miglioramento continuo.

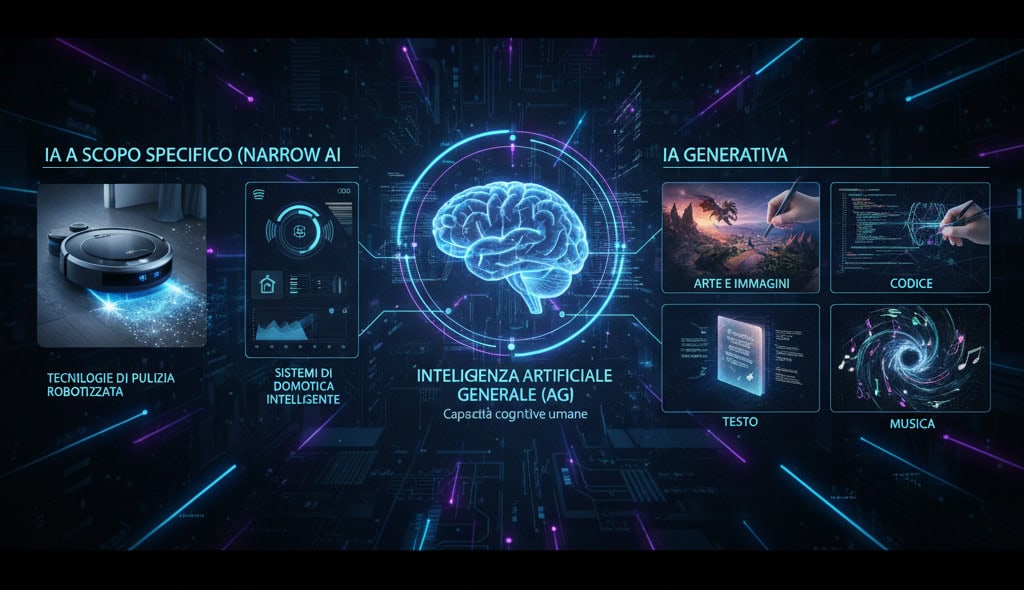
4. Tipologie, Applicazioni Pratiche e IA Generativa
L’IA si manifesta in diverse forme e applicazioni:
- IA a Scopo Specifico (Narrow AI): la forma più diffusa oggi, progettata per eccellere in un compito specifico. Esempi includono i motori di ricerca, i generatori di immagini e sistemi di automazione. In questo contesto, sono stati citati esempi pratici come:
- Tecnologie di pulizia robotizzata: dispositivi dotati di sensori che regolano la velocità e l’intensità della pulizia in base allo sporco rilevato, ottimizzando l’efficienza.
- Sistemi di domotica: Un hub centralizzato che usa l’IA per gestire i consumi energetici, ad esempio regolando tende e tapparelle in base alla luce solare per mantenere la temperatura ideale.
- Intelligenza Artificiale Generale (AGI): un’IA ipotetica con capacità cognitive paragonabili o superiori a quelle umane in qualsiasi dominio intellettuale. Sebbene sia ancora un obiettivo lontano e dibattuto, rappresenta la frontiera della ricerca.
Un’evoluzione chiave è rappresentata dai modelli generativi, algoritmi capaci non solo di analizzare dati, ma di creare contenuti originali (testo, immagini, codice, musica), dimostrando una capacità che va oltre la semplice rielaborazione.

5. L’Impatto sul Business e la Trasformazione del Lavoro
L’adozione dell’IA è diventata una priorità strategica per le aziende. Durante la sessione è stato evidenziato che l’83% delle imprese la considera cruciale per il 2025, con un potenziale ritorno sull’investimento (ROI) stimato al 42% per le web agency. I vantaggi concreti includono:
- Riduzione dei tempi e dei costi: fino al 65% di riduzione del tempo di debugging per gli sviluppatori e un aumento del 75% nella velocità di prototipazione per i designer.
- Evoluzione delle competenze: l’IA non sostituirà il lavoro umano, ma lo trasformerà. Emergeranno nuove professionalità e diventerà fondamentale la capacità di interagire efficacemente con i sistemi IA.
In questo scenario, gli Agenti AI rappresentano il passo successivo: non sono l’IA stessa, ma programmi che utilizzano gli LLM per eseguire compiti complessi in autonomia, come gestire lead commerciali o superare test di sicurezza come i “captcha”.
6. Interagire con l’IA: L’Arte del Prompt Engineering
Per sfruttare appieno il potenziale dell’IA generativa, è essenziale padroneggiare il prompt engineering, ovvero l’abilità di formulare richieste (prompt) chiare ed efficaci. Un prompt ottimale deve includere:
- Ruolo: “Agisci come un esperto di marketing…”
- Contesto: “sto preparando una campagna per un nuovo prodotto ecologico.”
- Compito: “scrivi tre slogan pubblicitari.”
- Dettagli: “lo stile deve essere ironico e il target sono i millennial.”
È fondamentale evitare istruzioni vaghe, generiche o contraddittorie per non compromettere la qualità dell’output.
7. Sfide, Etica e Regolamentazione
Nonostante il progresso inarrestabile, l’IA presenta sfide significative:
- Limitazioni e Allucinazioni: i modelli possono generare informazioni false ma plausibili (“allucinazioni”). È cruciale distinguere tra i limiti intrinseci del modello e le restrizioni imposte dalle piattaforme.
- Bias e Pregiudizi: se i dati di addestramento contengono pregiudizi (bias), l’IA li replicherà. È stato citato il caso di un sistema giudiziario statunitense che, addestrato su sentenze storiche, perpetuava discriminazioni.
- Copyright e Proprietà Intellettuale: l’uso di contenuti protetti da copyright per l’addestramento solleva complesse questioni legali sulla proprietà delle opere generate dall’IA.
- Controllo e Regolamentazione: l’
avanzamento dell’IA sarà accompagnato da una regolamentazione crescente. Il GDPR in Europa già pone limiti all’uso di dati sensibili. Spesso, le piattaforme che offrono accesso agli LLM (come ChatGPT o Gemini) implementano dei “guard rail” (barriere di sicurezza) che impediscono al modello di rispondere su argomenti sensibili (es. diritti umani, eventi controversi), anche se il modello di base ne avrebbe la capacità. Queste piattaforme possono inoltre integrare sistemi di verifica incrociata (es. con ricerche Google) per mitigare le allucinazioni e aumentare l’affidabilità delle risposte.
Contattaci per stare al passo con i tempi 😉
